
英伟达在 2016 年的强势崛起,GPGPU (GPU 通用计算)功不可没。
有许多原因使 2016 称得上是 GPU 之年。但事实上,除了在核心领域(深度学习、VR、自动驾驶),为什么把 GPU 用于通用计算仍然很模糊。
搞清楚 GPU 的作用,要先从 CPU 开始。大多数人对计算机 CPU 并不陌生,这可能要归功于英特尔——作为在事实上垄断了 PC、服务器平台 CPU 近十年的供应商,英特尔的巨幅广告支出,直接导致每个人都或多或少听说过英特尔从笔记本到超算的各层级产品。
CPU 的设计用途,是对多种应用进行低延迟处理。CPU 非常适合用于多功能任务,比如电子表格、文字处理、 Web 应用等等。于是,传统上 CPU 是绝大多数企业的首选计算方案。
过去,当公司的 IT 部门经理说要订购更多计算设备、服务器,或者增强云端的性能,他们一般想的是 CPU。
虽是个多面手,一枚 CPU 芯片能承载的核心数量却有很大限制。大多数消费级芯片只有八核。至于英特尔的企业级产品线,除了为并行计算而设计的 Xeon Phi 这个“怪胎”,主流至强产品(E3、E5、E7 系列)最多只有 22 核。
CPU 从单核发展到今天的多核用了几十年。对 CPU 这么复杂的芯片进行扩展有极高的技术难度,并且需要综合多个方面:比如缩小晶体管体积、降低发热和优化功耗等。今天的 CPU 在性能上所取得的成绩,很大程度上要归功于英特尔和 AMD 工程师的多年努力探索。而至今全球未有第三家足以与其 竞争的 PC CPU 供应商,在侧面说明了他们的技术积累,以及研发 CPU 的技术难度。
GPU 才是摩尔定律的宠儿?
用 FLOPS 来衡量,CPU 每年大约有 20% 的性能提升。而这是对于高度优化的代码而言。
随着 CPU 性能提升的放缓(雷锋网(公众号:雷锋网)注:尤其近几年来芯片制程工艺进步缓慢。硅基芯片的极限大约在 7nm,而替代硅的新技术尚未成熟),其数据处理能力越来越跟不上数据增长的速度。做个简单对比:IDC 估算,全世界数据增长的速度大约是 40%,并在不断加快。
简单来说,摩尔定律目前已终结,而数据却在指数级增长。
英特尔 Skylake、Kabylake、Coffelake 路线图
数据增长速度超过 CPU 性能提升速度带来的后果是:人们不得不利用各种技巧来避免计算性能瓶颈,比如降采样、索引(indexing),或者采用昂贵的 scale-out 战术来避免长时间等待系统回应。
我们现在面对的数据单位是 exabytes,并正在迈向 zetabytes。而曾经显得无比庞大的 TB,在消费者领域已经十分常见。企业级 Terabyte 存储的定价已降到个位数(美元)。
在这个价格,企业把所有获取的数据保存起来,这过程中,我们生成了足以淹没 CPU 级别数据处理能力的工作集。
这跟 GPU 有什么关系呢?
GPU 的架构与 CPU 很不一样。首先,GPU 并不具备多功能性。其次,与 消费级 CPU 个位数的核心数目不同,消费级的 GPU 通常有上千个核心——特别适合处理大型数据集。由于 GPU 在设计之初有且只有一个目的:最大化并行计算。每一代制程缩减直接带来更多的核心数量(摩尔定律对于 GPU 更明显),意味着 GPU 每年有大约 40% 的性能提升——目前来看,它们尚能跟上数据大爆炸的脚步。
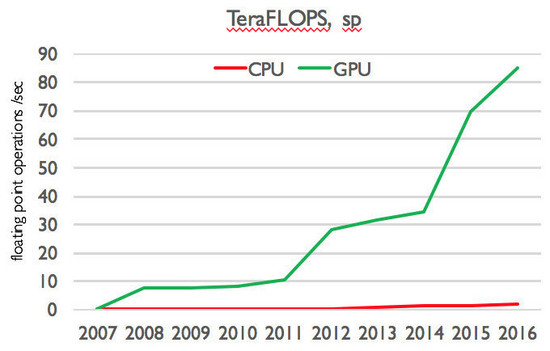
CPU 与 GPU 的性能增长对比,用 TeraFlops 衡量
GPU 诞生之初
在 90s 年代,一批工程师意识到:在屏幕上进行多边形图像渲染,本质上是个能并行处理的任务——每个像素点的色彩可以独立计算,不需要考虑其它像素点。于是 GPU 诞生,成为比 CPU 更高效的渲染工具。
简而言之,由于 CPU 在图像渲染方面的能力不足,GPU 被发明出来分担这部分工作,此后就成了专门搞这方面的硬件。
有了上千个更加简单的核心,GPU 能高效地处理让 CPU 十分吃力的任务。只要有合适的代码配合,这些核心就能处理超大规模的数学运算,实现逼真的游戏体验。
但有一点需要指出:GPU 的强大性能,不只来源于增加的核心数量。架构师们意识到,GPU 的处理性能需要有更快的内存相配合才能发挥。这让研究人员不断研发更高带宽版本的 RAM 内存。今天,GPU 的内存带宽相比 CPU 已经有数量级上的领先,比如前沿显存技术 GDDR5X,HBM2,还有开发中的 GDDR6。这使得 GPU 在处理和读取数据上都有巨大优势。
有这两大优势,GPU 在通用计算领域有了立足点。
GPU 与 CUDA
事实证明,高端游戏玩家和计算机科学家在硬件需求上有不少交集。计算机科学家们逐渐发现,利用 GPU 的大量核心执行复杂数学运算,在 HPC 领域有巨大应用前景。但是,写出能高效运行于 GPU 的代码极度困难。想要驾驭 GPU 计算性能的研究人员,必须把相关运算“黑进”图形 API,让显卡以为要处理的计算任务和游戏一样:决定像素色彩的图像渲染计算。
但一切在 2007 年发生了变化。这一年,英伟达发布了 CUDA(Compute Unified Device Architecture)。 它支持 C 语言环境的并行计算。对于那些靠 C 语言发家的程序猿,他们可以直接开始写基础的 CUDA 代码,一系列运算任务从此可以很容易地并行处理。
CUDA 诞生的结果是:似乎在一夜之间,地球上的所有超级计算机都采用了 GPU 运算。深度学习、自动驾驶以及其他 AI 领域开始焕发光芒。
并行计算
并行计算是发挥 GPU 性能的关键。这意味着你可以同时处理运算,而不是一步步进行。复杂问题可被分解为更简单的问题,然后同时进行处理。并行计算适用于 HPC 和超算领域所涉及的许多问题类型,比如气象、宇宙模型和DNA 序列。
并不是只有天体物理学家和气象学家才能充分利用并行计算的优点。事实证明,许多企业应用能从并行计算获得超出寻常比例的好处。这包括:
数据库查询
密码学领域的暴力搜索
对比不同独立场景的计算机模拟。
机器学习/深度学习
地理可视化
你可以联想一下你们公司所面临的数据问题——那些数据量和复杂程度极高,你以前连想都不敢去想怎么处理,但深层次分析很有可能会有助于解决的问题。我怀疑这样的问题是可并行计算的——而 CPU 层次的计算解决不了,不代表 GPU 也不行。
CPU vs. GPU 小结
作为小结,GPU 在以下方面有别于 CPU:
一枚 GPU 芯片有几千个核心。通常意义的 CPU 最多只有 22 个。
GPU 为高度并行的运行方式而设计。CPU 为一步步的连续计算而设计。
GPU 的内存带宽比 CPU 高得多。
CPU 适合于文字处理、运行交易数据库、网络应用等场景。 GPU 适用于 DNA 排序、物理建模、消费者行为预测等任务。
经济成本
上文中,我讨论了问什么 GPU 代表着计算的将来。但它的商用价值如何呢?
GPU 在经济成本上其实占优势。首先,一个完整的 GPU 服务器比一个完整的 CPU 服务器要贵很多。但两者之间难以直接对比。一个完整的 8 路 GPU 服务器,成本可达八万美元。但一个中等的 CPU 服务器配置大约只需要 9000 刀。当然,RAM 和 SSD 的使用量对价格有很大影响。
咋看之下,CPU 好像比 GPU 划算多了。但请注意,250 个这样的“中等” CPU 服务器在并行计算性能才相当与一台如上所说的 GPU 服务器(雷锋网注:只是作者个人的估算,以支撑他的观点,大家看看就好)。
很明显,如果你要做的只是并行计算,选择 GPU 服务器要划算多了。极端情况下,如果硬要上 250 台 CPU 服务器,加上电费、场地费、网费、温控、维护管理费,最终价格会是天文数字。因此,如果并行计算占了公司工作量的大部分,从投资回报率的角度,GPU 是正确的选择。
对生产力的影响
在延迟对数据分析的影响方面,我已经写了很多。我的基本论点是:当一个开发者需要等待几分钟才能得到查询结果,人的行为会发生变化。你开始找捷径,你开始用更小的数据集执行查询操作,你只会执行不耗费时间的查询,你不再探索——执行几个查询就把这当做是方向。
提高计算机响应速度对生产力的提升很难衡量。但你可以想一想,宽带时代和拨号时代的生产力差别。
最后,在云时代,与其建立自己的 GPU 服务器, 租用 GPU 云计算服务对于很多客户来讲十分划算。GPU 计算的门槛已经无限降低。
在线咨询
请输入您的问题:
提示:系统优先提供真人服务。非工作时间或繁忙时,会由 AI 生成回答,可能存在错误,请注意甄别。