
北京时间3月9日下午消息,今天下午谷歌人工智能AlphaGo与韩国棋手李世石的第一场比赛结束,AlphaGo获得今日比赛的胜利。双方在较量3个半小时后,李世石宣布认输。今日比赛结束后,双方还将分别在3月10日(周四)、12日(周六)、13日(周日)、15日 (周二)的北京时间中午12点进行剩余4场比赛。
本次比赛用时每方2小时,1分钟读秒三次。比赛采用中国规则,黑贴3又3/4子(黑贴7目半)。采用中国规则是因Alpha GO以中国规则为基础开发。
比赛采用5局3胜制,最终比赛获胜方将获得奖金100万美元。如果AlphaGo获胜,奖金将捐赠给联合国儿童基金会(UNICEF),STEM教育,以及围棋慈善机构(Go Charity)。
AlphaGo开发者DeepMind公司在今年1月的学术杂志《Nature》刊登封面文章,展示了围棋人工智能领域突破性进展的详细情况。这次对弈中,坐在李世石对面正是《Nature》封面文章作者之一黄士杰(Aja Huang),他本人来代替AlphaGo在棋盘上落子。AlphaGo一方的旗帜是英国国旗,因为这次参赛的谷歌围棋程序AlphaGo来自英国人工智能公司DeepMind。
谷歌AlphaGo在第一次与世界顶尖围棋手的较量中取得胜利,这是人工智能发展史上重要的里程碑,代表人工智能已经能在诸如围棋等高度复杂的项目中发挥出超过人类的作用。
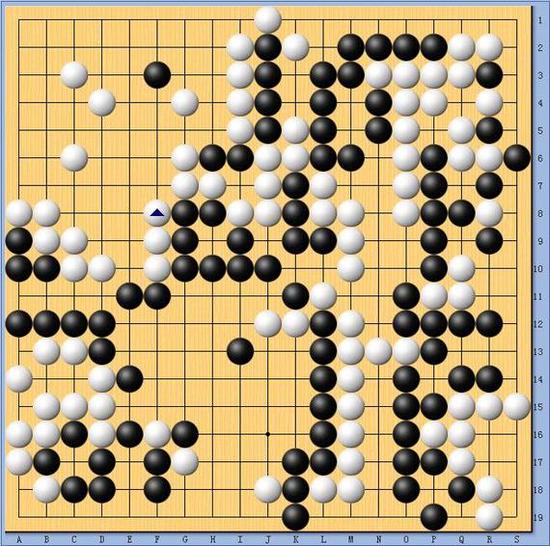
AlphaGo与李世石对战棋谱AlphaGo与李世石对战棋谱
一般来说,现在的职业围棋高手喜欢下白棋,但李世石有些出人意料地第一盘选择了执黑先行。很快李世石给出了理由,黑棋布局走出了一个新型,阿尔法的应对不佳,有些亏损。李世石显然研究了电脑围棋的理论,得出了电脑在布局阶段不太擅长应对新型的推论,棋局的进行证明了这一点,李世石有备而来。
不过围棋决定胜负的往往是中盘阶段,阿尔法似乎也“意识”到了自己形势不佳,之后的下法选择得非常强硬,双方早早就展开了接触战。电脑的下法令观战的职业棋手目瞪口呆,几乎招招都是最佳应对。好在战斗也是李世石的强项,双方就像武林高手,猛对几掌,然后各自退了好几步。
不过在第一个战役结束之后,电脑的选择令人费解。正常高手,对掌之后,总要运气缓一下,然后再打,电脑的下法则是直接又扑上来了。过刚易折,这处的战役,李世石抓住机会,围住一块大空。人族代表心里有底了,电脑虽然在局部战斗表现出色,但在大局上似乎不如人类高瞻远瞩。
不过作为人类最大弱点是会受情绪波动的影响,取得优势后,李世石的心态似乎发生了变化,右下角黑棋下得太过保守,白棋左右逢源,角部做活,大龙也及时补棋,黑棋一无所得,此前的优势消失殆尽。各路讲解的职业棋手判断也出现了分歧,不过随着棋局进入官子阶段,大家发现李世石其实败局已定。
最终李世石投子认负,表情上看上去不是很痛苦,不知是不是找到了电脑的弱点?
谷歌为何要做人工智能围棋程序AlphaGo
谷歌并不只是想做一个棋类程序,而是想做一个通用的智能计算系统。如果解决了围棋问题,谷歌希望能把这套人工智能算法用于灾害预测、风险控制、医疗健康和机器人等复杂领域。也就是说谷歌的目的还是为了更好的服务人类,没有任何恶意。DeepMind(AlphaGo的研究公司)创始人哈萨比斯说:公众对人工智能的警示掩盖了人工智能带来的帮助。距离人脑水平的人工智能仍然相当遥远,可能还需要几十年。
在昨天的赛前发布会上,谷歌董事长施密特表示,输赢都是人类的胜利。因为正是人类的努力才让人工智能有了现在的突破。
但并不是所有人都会对人工智能持乐观态度。诸如特斯拉CEO马斯克、理论物理学家霍金等科技界的名人就对此产生了担忧。
围棋复杂度超过宇宙原子总数
围棋棋盘横竖各有19条线,共有361个落子点,双方交替落子,这意味着围棋总共可能有10^171(1后面有171个零)种可能性。这个数字到底有多大,你可能没有感觉。我们可以告诉你,宇宙中的原子总数是10^80(1后面80个零),即使穷尽整个宇宙的物质也不能存下围棋的所有可能性。
19年前,IBM公司的“深蓝”计算机战胜了国际象棋世界冠军卡斯帕罗夫,引起了巨大轰动。但是因围棋的复杂度,直到近期,人类才在围棋人工智能项目上取得重大突破。
由于围棋的可能性如此之多,根本就没有什么套路可言。下赢围棋的唯一的办法就是让电脑也学会“学习”,而不是死记硬背。为了在围棋上战胜人类,硅谷的两家科技公司——Facebook和谷歌开始研究,希望有朝一日能让计算机战胜人类围棋冠军。

李世石与AlphaGo对弈李世石与AlphaGo对弈
李世石简介
李世石是李昌镐之后,韩国最具代表性的棋手,他在2003年获第16届富士通杯冠军后升为九段棋手。自2002年加冕富士通杯以来,十年时间里他共获18个世界冠军。李世石属于典型的力战型棋风,善于敏锐地抓住对手的弱处主动出击,以强大的力量击垮对手,他的攻击可以用“稳,准,狠”来形容,经常能在劣势下完成逆转。
AlphaGo去年10月击败欧洲冠军
谷歌曾于2014年以4亿欧元收购人工智能公司DeepMind。由DeepMind研发的AlphaGo项目已有两年历史,AlphaGo曾在去年战胜了欧洲围棋冠军樊麾(职业二段)。
去年10月5日-10月9日,谷歌AlphaGo在比赛中以5:0的比分完胜了欧洲冠军。除了战胜人类外,AlphaGo还与其他的围棋程序对战,获得了500场胜利。
AlphaGo原理简介
传统的人工智能方法是将所有可能的走法构建成一棵搜索树 ,但这种方法对围棋并不适用。此次谷歌推出的AlphaGo,将高级搜索树与深度神经网络结合在一起。这些神经网络通过12个处理层传递对棋盘的描述,处理层则包含数百万个类似于神经的连接点。
其中一个神经网络“决策网络”(policy network)负责选择下一步走法,另一个神经网络“值网络”(“value network)则预测比赛胜利方。谷歌方面用人类围棋高手的三千万步围棋走法训练神经网络,与此同时,AlphaGo也自行研究新战略,在它的神经网络 之间运行了数千局围棋,利用反复试验调整连接点,这个流程也称为巩固学习(reinforcement learning)。通过广泛使用Google云平台,完成了大量研究工作。
AlphaGo在与人的对弈中用了“两个大脑”来解决问题:“决策网络”和“值网络”。通俗来说就是,一个大脑用来决策当前应该如何落子,另一个大脑来预测比赛最终的胜利方。
值得一提的是,李世石也是第一次与机器对战,所以他无法像和人类对战那样,先研究对方的棋谱和下棋风格。李世石所能做的就是和自己对弈。谷歌AlphaGo也是通过这种方式锻炼自己,真正做到了“人工智能”。
来源:新浪科技讯 边策 周游
在线咨询
请输入您的问题:
提示:系统优先提供真人服务。非工作时间或繁忙时,会由 AI 生成回答,可能存在错误,请注意甄别。